Tracking protection
Tracking protection, and similar measures, seek to protect the user from covert data collection and exploitation by scripts and applications created for such purposes.
In short, tracking protection, tracking prevention, anti-tracking, cookie blocking, content blocking, etc. are designed to:
- Identify and classify domains that utilize and distribute tracking mechanisms obstructive to (browsers’ interpretation of) web user privacy.
- Restrict storage access in third-party context for such scripts so that the trackers cannot build cross-site profiles of web users.
- In some cases, restrict storage access in first-party context where it’s likely that it could be exploited for cross-site tracking purposes.
In this introductory chapter, we’ll gloss over some of the key terminology regarding tracking protection. You are then advised to visit the other pages of Cookie Status for more details.
Cookies
Browser cookies are key-value pairs (e.g. id=abcd1234) of information stored on the user’s computer. Websites set them in order to persist information from one page to the next. This is because the web is effectively stateless - only a very limited set of information is shared from one page to the next. By writing information into browser storage, that information persists even if the pages the user navigates from are unloaded and their storage purged.
Typical use cases for cookies include persisting a shopping cart from one page to the next on an ecommerce site, storing details about user’s login status, and for setting an identifier for the user, so that their visits can be recognized in an analytics tool as originating from the same browser.
Websites can write cookies on the user’s computer, and they can read cookies from the user’s computer. How effective this is depends on whether the user’s browser allows cookie access in third-party context, and whether cookies in first-party context have restrictions as well.

First-party cookies set on the current domain and on the eTLD+1
Reading cookies
Cookies can be read and written in two ways: with HTTP headers and with JavaScript.
The first method relates to the browser requesting resources from a web address. This is done via an HTTP request.
When the browser requests a resource from a web address, that request will include a cookie header, which includes all the cookies written on the target domain and all the domains in its domain hierarchy up to the eTLD+1.
eTLD+1 means effective top-level domain plus one part. The eTLD is the same thing as the Public Suffix. For a domain like blog.ecommerce.cookiestatus.co.uk, the eTLD would be .co.uk, and the eTLD+1 would be cookiestatus.co.uk. For a domain such as cookiestatus.github.io, the eTLD would be github.io and the eTLD+1 would be cookiestatus.github.io.
This is what a sample HTTP request would look like with the cookie header in place:
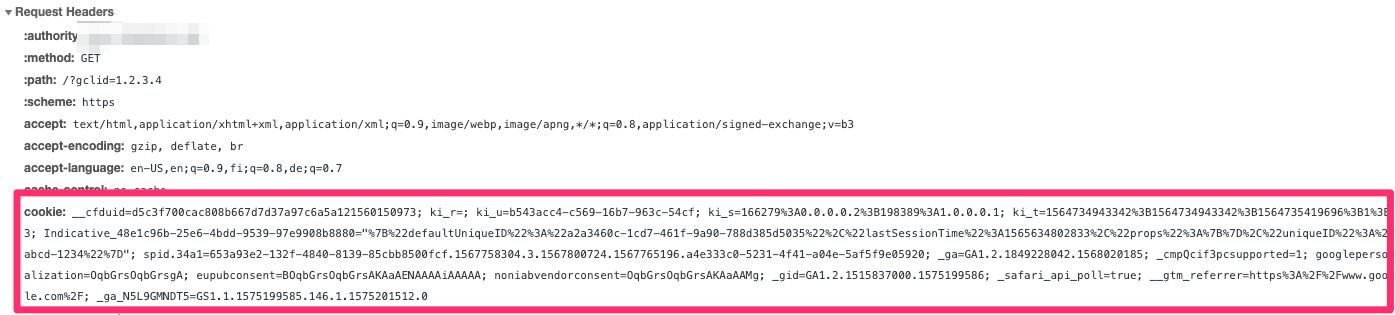
Sample cookie header with all cookies available on the target domain
The cookie header must respect the cookie settings in the browser. If the browser blocks third-party cookies, the cookie header is only included for requests in first-party context. Similarly, if the browser blocks all cookies, the cookie header will not be included in any requests.
Because the cookie header is part of the HTTP request, it means that the web server hosting the resource will be able to read this header and use this information at will.
The browser can read cookies with JavaScript as well.
While the user is browsing a website, that website can use JavaScript to read the cookies written on the current domain and all the domains up to the eTLD+1.
const cookies = document.cookie;
console.log(cookies); // userId=abcd1234; logged-in=true
If document.cookie is invoked in a third-party context, such as an <iframe> element embedding content from a third-party source, the string will be populated only if the web browser allows third-party cookies.
Since the cookies are readily available for any JavaScript running on the page, a malicious vendor with a script running on the site could utilize the API to read and process the cookies stored on the user’s company.
Writing cookies
Similar to reading cookies, the HTTP protocol can be used to write cookies as well. The web server can return with an HTTP response including the Set-Cookie header.
This header is an instruction to the browser to write the included cookie(s) on the domain specified in the header.

Sample Set-Cookie header with instructions on which domain to write the cookie
Using JavaScript, the document.cookie API can be used to write cookies, too.
While on the www.cookiestatus.com domain, the following command would write a userId cookie on cookiestatus.com.
document.cookie = 'userId=abcd1234;domain=cookiestatus.com;path=/';
Web servers and JavaScript libraries can thus write cookies on the eTLD+1, which means they become automatically available to all subdomains of that host. Thus a script running on blog.ecommerce.cookiestatus.com can check if the user has an identifier written on cookiestatus.com, and utilize that. This can be abused for cross-site tracking purposes.
First-party and third-party context
It’s common in the parlance of the web to talk about first-party cookies and third-party cookies. This is a bit of a misnomer. Cookies are pieces of information that are stored on the user’s computer. There is no distinction between first-party and third-party in how these cookies are classified and stored on the computer.
What matters is the context of the access.
Nevertheless, to align with other discussions around the same topic, Cookie Status will use first-party cookie and third-party cookie for clarity’s sake.
First-party context means that the operation happens between domains within the same site, í.e. domains that share the eTLD+1. Third-party context means that the operation happens cross-site, i.e. between domains that do not share the eTLD+1.
Here are some examples. Consider the user to be on the domain www.cookiestatus.com.
| Scenario | Type of context | eTLD+1 | Details |
|---|---|---|---|
| The browser requests an image from images.cookiestatus.com. | First-party context | cookiestatus.com | The cookie header includes all cookies written on images.cookiestatus.com and cookiestatus.com. The Set-Cookie header can write a cookie on *.cookiestatus.com. |
| The browser loads a JavaScript file from cdn.vendor.com. | Third-party context | cookiestatus.com vs. vendor.com | The cookie header includes all cookies written on cdn.vendor.com and vendor.com. The Set-Cookie header can write a cookie on *.vendor.com. |
The browser runs document.cookie on the page in the top frame (the main window). |
First-party context | cookiestatus.com | The command can be used to read and write cookies on www.cookiestatus.com and cookiestatus.com. |
The browser loads a page from booking.vendor.com in an <iframe> and runs document.cookie on that page. |
Third-party context | vendor.com | The command can be used to read and write cookies on booking.vendor.com and vendor.com. |
In the first-party context scenarios above, the cookie read/write operations will work unless the browser blocks all cookies or has cookiestatus.com in a blacklist.
In the third-party context scenarios, the cookie operations will work unless the browser blocks all third-party cookies, has vendor.com in the blacklist, or the possible tracking protection mechanisms have deemed vendor.com to be a tracking domain.
Cookie access in a first-party context is rarely blocked, because many features of modern websites rely on state management in the browser (using cookies or other browser storage). However, some vendors are repurposing first-party cookies for cross-site tracking, which has led to browsers (especially Safari) to place restrictions on first-party storage as well.
Accessing cookies in a third-party context is necessary for some benign features of the web, such as persisting user authentication across the domains of an organization (SSO), or for passing information about user’s marketing consent from one part of the organization to another.
However, cookie access in a third-party context can be abused as well, because it can be used for cross-site tracking without the user’s consent or awareness.
Cross-site tracking
A common thread in the rhetoric is that browsers want to quench cross-site tracking. Here’s how Safari describes it:
Imagine a user who first browses example-products.com for a new gadget and later browses example-recipies.com for dinner ideas. If both these sites load resources from example-tracker.com and example-tracker.com has a cookie stored in the user’s browser, the owner of example-tracker.com has the ability to know that the user visited both the product website and the recipe website, what they did on those sites, what kind of web browser was used, et cetera. This is what’s called cross-site tracking and the cookie used by example-tracker.com is called a third-party cookie. In our testing we found popular websites with over 70 such trackers, all silently collecting data on users.
In essence, cross-site tracking utilizes centralized tracking domains for scripts to communicate with from the sites the user actually visits. These tracking domains leverage third parties’ access to browser storage (mainly cookies) to build profiles of all the sites the user has visited.
Cross-site tracking
To continue the examples from the previous chapters, when the user’s browser makes a request for image.imagestore.com while on the blog.ecommerce.cookiestatus.com website, the endpoint at image.imagestore.com will now know that the request originated from blog.ecommerce.cookiestatus.com, as this is included in the origin and referer [sic] headers.
Thus the endpoint at image.imagestore.com could now check if the user has an identifier cookie set on that domain, and they can augment the profile for that identifier with knowledge that the user has visited blog.ecommerce.cookiestatus.com.
If the user then visits another page on the internet that also communicates with image.imagestore.com, then that endpoint will be privy to yet another origin, and they can keep building the profile.
This is the essence of cross-site tracking - using a consolidated and centralized store (e.g. a cookie) to collect information from different domains.
Storage access restriction
Browsers’ main weapon against cross-site tracking is restricting storage access. Because there are valid reasons for cross-site tracking (persisting user authentication, shopping baskets, consent status), tracking protection methods restrict storage access for third parties that have been identified and classified as compromising user privacy.
All major browsers now partition storage in some way. Partitioning means that storage access isn’t necessarily blocked, but it is keyed between two cross-site origins.
For example, site b.example, when embedded on a.example, would have access to its cookies and other storage mechanisms, but these mechanisms would be unique to the combination of b.example–a.example. If another site, such as c.example, were to embed content from b.example, they would have a new, unique partition for storage which would be different from what was available when accessed via a.example.
List-based protection
Mozilla Firefox, for example, describes their own effort like this:
In order to help give users the private web browsing experience they expect and deserve, Firefox will strip cookies and block storage access from third-party tracking content, based on lists of tracking domains by Disconnect.
This approach of comparing the third-party domains against a curated list is utilized also by Microsoft Edge. Here’s how they introduce Edge’s tracking prevention:
We’ve added a new component to Microsoft Edge, Trust Protection Lists**,** that contains the latest information on which organizations may be trying to track users on the web. This component allows us to be flexible with where we source details on what a tracker is and when we deliver updated lists to our users.
The Brave browser, similarly, pulls in tracking domains from multiple sources. Notably, Brave combines prescribed lists (from e.g. EasyList and uBlock Origin) with a more dynamic list based on crawl data (PageGraph).
With list-based protection, the browser maintains a list of domains against which each outgoing HTTP request from the site is pattern-matched. If there is a match between the request target and one of the domains in these lists, the request is blocked.
This means that browsers can block both downloading script resources and HTTP requests to tracking endpoints (e.g. image pixels).
By blocking the script download, browsers don’t need to worry about further storage access restrictions, because the JavaScript from the vendor was never loaded and thus can’t abuse the browser storage on the user’s company.
By blocking the pixel and other HTTP endpoints, browsers ensure that in cases where the site is loading the JavaScript from a non-blocked source, the script will not be able to communicate with its endpoint.
The biggest problems with list-based protection are:
- The performance overhead of pattern-matching each HTTP request against an ever-growing list of domains (something that these browsers are actively optimizing).
- Reaction lag to new trackers and domains that need to be blacklisted.
- Difficulty in handling locally cached and/or proxied requests.
- Harm to other functionality (besides tracking) that these blocked libraries provide.
Algorithmic protection
The Safari browser has opted for a different tact. Instead of a binary approach (blocked vs. not blocked) and a set list of domains, Safari’s Intelligent Tracking Prevention uses multiple methods to restrict the storage access for third parties that are algorithmically classified as having cross-site tracking capabilities. Here’s how they describe the classification process:
A machine learning model is used to classify which top privately-controlled domains have the ability to track the user cross-site, based on the collected statistics. Out of the various statistics collected, three vectors turned out to have strong signal for classification based on current tracking practices: subresource under number of unique domains, sub frame under number of unique domains, and number of unique domains redirected to. All data collection and classification happens on-device.
Note that in early 2020, WebKit’s tracking protections were extended to block all third-party cookies without exception. Thus the algorithmic classification no longer applies to how third-party storage is accessed, but it is still used for other tracking-related protections (such as downgrading the referrer).
However, Safari’s approach is binary in a sense - you can either enable all cross-site tracking or none.
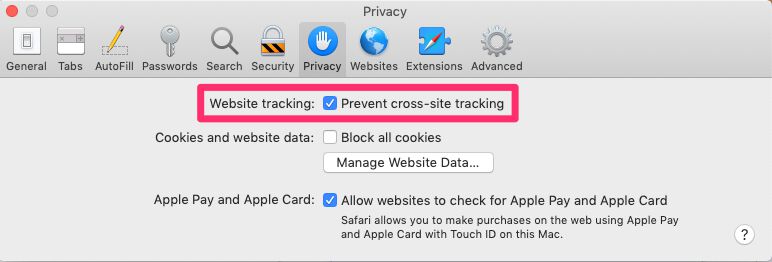
Safari privacy settings
Cliqz has a similar tact. This is explained in detail in this research paper, and in this blog post. Basically, they combine local and global evaluation of the data passed to and from the web browser to establish heuristical models for identifying potential tracker connections.
Cliqz’ approach is two-fold. First, they purge identifiers from the HTTP requests that could be misused for tracking. Second, they block cookie access in third-party context, unless the user interacts with the third-party domain (e.g. in a widget).
A global safe set is compiled from the actions Cliqz’ anti-tracking mechanism takes on each individual browser, and this global research data is used to fine-tune the local behavior of Cliqz’ tracking protections.
The algorithmic approach is effective because it identifies potential tracking domains dynamically and without using a centralized list. This means that there’s less overhead in pattern-matching the HTTP requests as the list of domains for the browser would only include those the browser has actually communicated with.
The algorithm also ensures that locally hosted tracking domains and reverse proxies would also be under scrutiny (unless served in a same-site context).
The main problems with this approach are:
- False positives, where the algorithm classifies domains that serve no cross-site tracking purpose, or purges identifiers that are not used for tracking.
- There is also some reaction lag, because the algorithm would require enough data to classify each new domain. It’s thus possible some communication with a tracking domain would be permitted before access is restricted.
- Lack of predictability, which is not necessarily a problem or a bad thing, but a list-based approach allows for community oversight of the domains that have been blacklisted.
Note that for false positives blocking access to cross-origin storage, ITP offers the Storage Access API. However, there is no provision in ITP to remove a domain from the list of classified domains, which means that first-party protections would still apply.