Summary of exploits
There are a number of ways in which data exploitation is attempted by malicious trackers. On this page, these will be listed superficially.
The problem is that all these methods also serve valid and benign use cases, which means that when browsers seek to prevent these, they also end up preventing non-malicious and non-exploitative use of browser storage.
And this is the nature of the beast. The very same APIs and methodologies that are used, for example, to improve the user experience of the site are simultaneously being repurposed by third parties for data collection and manipulation.
See the chapter on Impact for more details on how countering these exploits is impacting other, potentially benign use cases.
The exploits listed here are:
Cookies in third-party context
Leveraging browser cookies in third-party context (so-called third-party cookies) is the age-old way how advertising technology vendors build audiences for improving their targeting mechanisms.
By observing the user’s browsing behavior across the web, ad tech vendors can build robust profiles and deduce the user’s interest and affinity groups based on the sites they visit. Naturally, the robustness of this profiling depends on how many sites are included in this network, which is why large technology companies have the upper hand due to an extended reach and an established ecosystem.
These vendors are able to build these audiences if the user’s browser does not block access to third-party cookies.
For example, if you browse a site that has a Google DoubleClick pixel firing, or has Google Analytics set up so that the site communicates with DoubleClick servers, you might see the following network request:

Request to DoubleClick on the first site
It’s a request to DoubleClick’s domain (the request URL is something like https://1234567.fls.doubleclick.net/activityi...). As you can see in the cookie header, the user’s browser has cookies set on this domain, and one of these cookies is named DSID with a long, hashed identifier string.
Now, visit another, completely different site that also sends requests to DoubleClick servers and observe the network requests:

Request to DoubleClick on the second site
It’s another request to DoubleClick. This time the subdomain might be different, e.g. https://98765432.fls.doubleclick.net/activityi..., but since the cookie is written on the eTLD+1, you can see the result in the screenshot:
The DSID value is exactly the same as on the other website.
Thus, when you visit these two sites without restricting access to third-party cookies, DoubleClick will know that your particular DSID is now associated with visits to these two websites.
This type of covert tracking is called cross-site tracking, and it can be used by vendors to build their own profiles. However, it can also be abused by data management platforms (DMPs) that participate in cookie matching between multiple vendors to build an even larger user database.
Unfortunately, this very same method is used for benign scenarios, such as persisting user authentication across different websites of the same organization.
If cookies in third-party context are blocked by the browser, then there are other means to achieve the same type of profiling, such as by repurposing the first-party context.
Link decoration
When vendors find out that their attempts to leverage cookies in third-party context are thwarted, they will repurpose the first-party context to continue tracking users across websites.
For example, if the vendor has a first-party ecosystem (such as a social media platform or a suite of products behind a shared authentication) coupled with an ad tech network (or they participate in cookie matching), they are well positioned to hijack first-party storage to build a profile of visitors.
Repurposing first-party context is more effective if the vendor has a first-party service to which the user can log in. Services that only exist in third-party contexts (such as display networks) are most vulnerable to tracking protection measures.
When the user is logged in to the vendor platform, they have a unique identifier that the vendor can use to recognize them. There is nothing exceptional about this - it’s exactly how any login would authenticate a user.
However, what the vendor can then do is decorate every single link leading out of the platform with a hash containing the user’s unique identifier. Thus a link like https://www.cookiestatus.com/ now becomes https://www.cookiestatus.com/?vendorid=ABCDefgh1234IJKL5678mnop.
When the user follows the link, all it takes is for any one of the vendor’s JavaScript libraries (or a collaborating partner’s JavaScript libraries) to run on the site for the ID to be written into first-party storage as a cookie, thus being impervious to third-party context blocking, and to be sent with e.g. remarketing or conversion pixel requests back to the vendor.
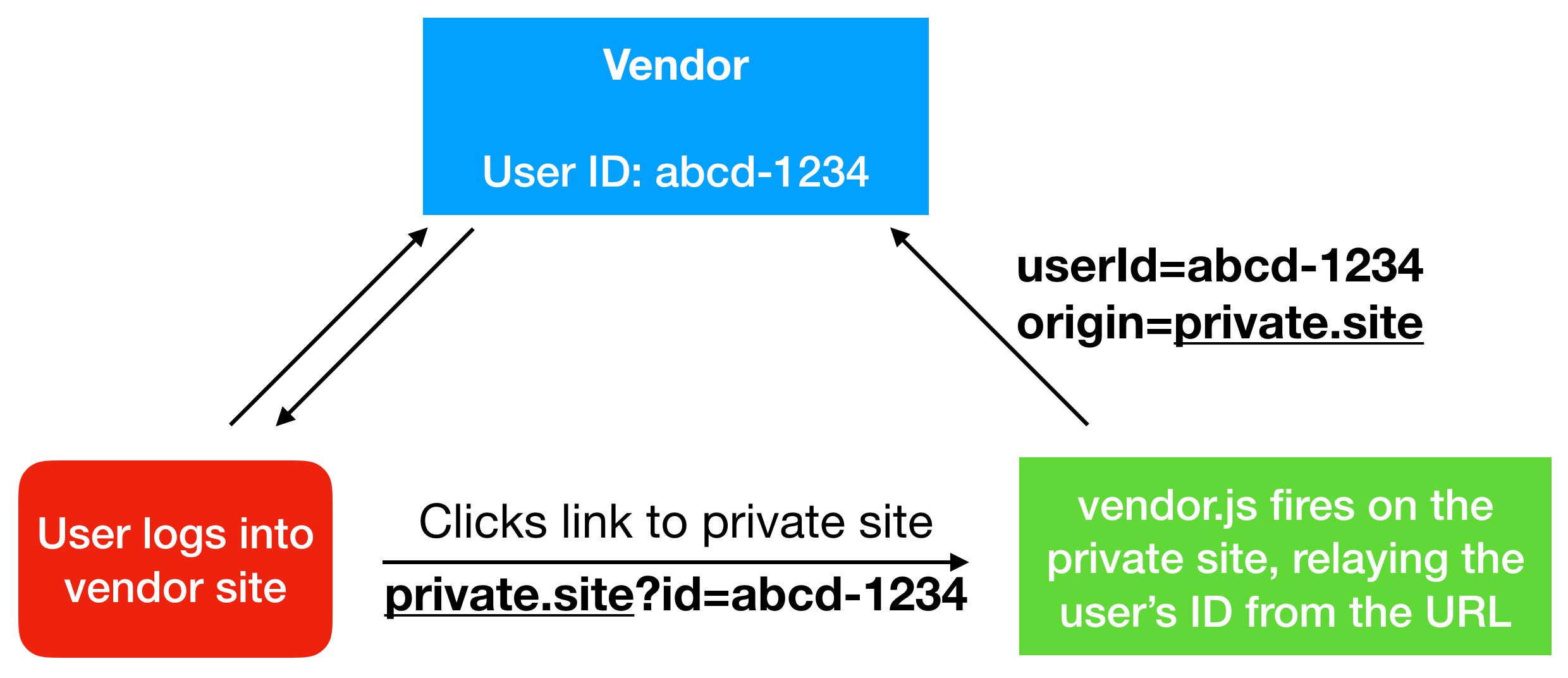
URL decoration by vendors
This way the vendor will know that the logged-in user not only followed the link, because they can track clicks on the link, but they’ll also know what they did on the target site due to the JavaScript firing on that site and communicating this information back to the vendor.
Link decoration is not always reliable. Sites might introduce redirects that strip parameters from the URL (or break if non-whitelisted parameters are added), and tracking protection mechanisms (especially ITP) can be used to handicap first-party storage when link decoration is involved. Thus vendor platforms can also decorate the referrer string to avoid having their identifiers paraded in the URL of the target site.
Referrer decoration
Referrer decoration works exactly the same as link decoration, except instead of decorating the URL to which the user is navigated, the service creates an intermediate page through which the user is redirected.
This page would have the user identifier in its URL.
By doing so, the document.referrer string (and the referer HTTP header) would include the identifier, and the vendor’s JavaScript libraries could, again, use this information to relay the user’s navigation patterns back to the vendor.
Referrer decoration is resilient to things like redirects stripping out query parameters of the target URL, and due to browsers’ referrer policies, it is not a very reliable way to pass information from one site to the other.
Browsers are taking a stronger stance against leaking information in referrers, adopting policies like strict-origin-when-cross-origin by default (this would strip referrer strings to their hostnames when the request is not same-site). Safari’s intelligent tracking prevention is going even further, stripping document.referrer to eTLD+1 (so https://my.site.com/?id=12345 would become https://site.com) in cross-site tracking scenarios.
If the vendor does not have a strong enough first-party ecosystem to decorate links or referrers with user identifiers, they can attempt cross-site tracking through browser and device fingerprinting.
Fingerprinting
Fingerprinting is a methodology where user’s browser and device settings, at least those that are exposed to JavaScript APIs and HTTP headers, are used to build a digital fingerprint of the user’s browser instance.
The logic is that since the user is very likely to use the same browser and device when browsing the web, this fingerprint can be utilized on different websites to uniquely identify the user.
Individual flags in the fingerprint (such as browser name, version, timezone) are not capable of recognizing a user, but the more flags that are added the higher the entropy, and the more likely the user can be uniquely identified by the combination of these browser settings.
Fingerprint APIs that utilize hardware configurations, such as Canvas, Web Audio, and WebGL are most robust, especially when used together. These are also the APIs most targeted by fingerprinting prevention measures.
You can use the AmIUnique service to check how unique your current fingerprint is.
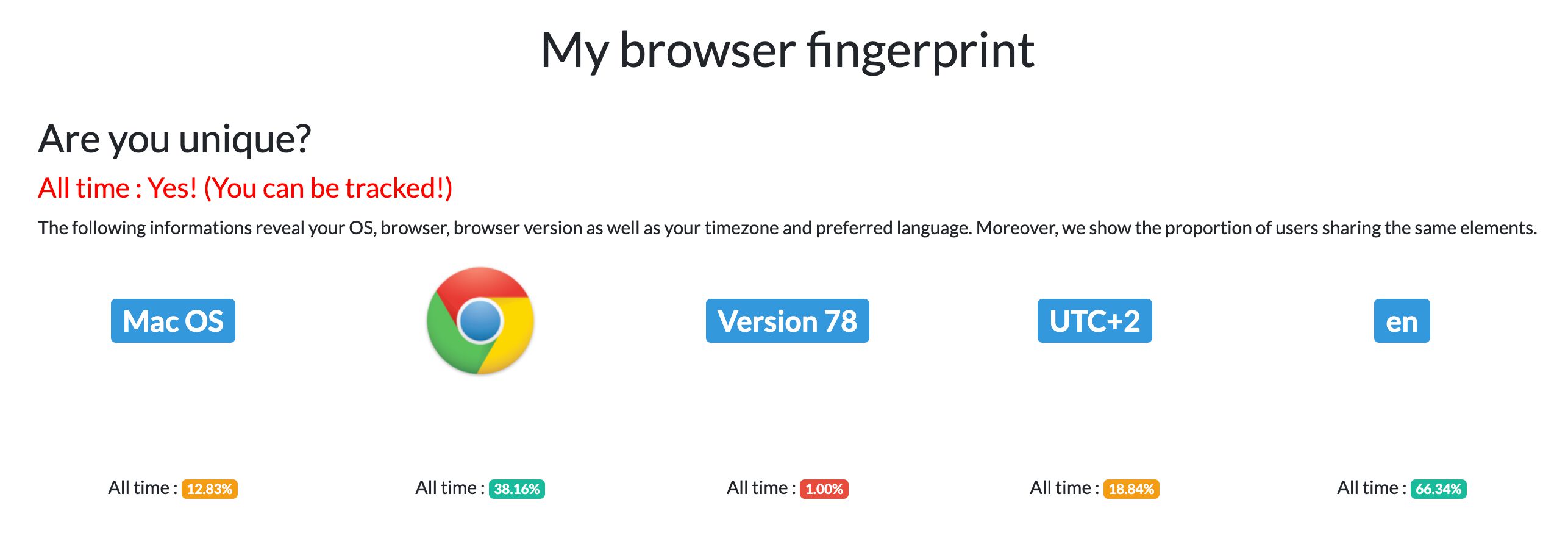
Sample AmIUnique result
Browsers are coming down strongly on fingerprinting. Chrome introduced the privacy budget as a concept they’re looking into, Safari is actively reducing potential fingerprinting surfaces, Firefox is blocking scripts that distribute fingerprinting tools (as is Edge), and then there are browsers like Brave where fingerprinting protections are front-and-center of development.
CNAME records
Sometimes the web browser is just too unreliable for vendors to leverage efficiently for their cross-site tracking purposes.
All the exploits listed above have native preventions in place in many browsers, and there are also browser extensions that help with tracking protection as well.
This is why some vendors recommend site owners to set up new domains in their own domain namespace (thus becoming part of first-party context), but instead of pointing to a server owned by the site, the domains would be mapped to vendor servers.
A simple way to accomplish this is with a CNAME (canonical name) DNS record. The CNAME record maps a hostname such as tracker.domain.com to a canonical domain name (e.g. abcd123.tracking-vendor.com), provided and owned by the vendor.
The website can then make requests to tracker.domain.com, and the request would be transferred through the CNAME chain all the way to the web server owned by the vendor. Thus the vendor would have access to all cookies written on tracker.domain.com and domain.com.

CNAME record in DNS settings
It doesn’t solve cross-site tracking by itself, because the endpoint would only have access to cookies written on domain.com (and not, e.g. vendor.com), but by sending the identifiers from link decoration or referrer decoration, or by fingerprinting the browser, the vendor can continue profiling the user with little risk of getting the domain blacklisted.
There are serious security issues involved with surrendering subdomains to third parties, so site owners should consistently and carefully audit any traffic passing through their domains.
Browsers can’t natively resolve CNAME records for a given hostname (apart from Firefox, to some extent). However, identifying known trackers in CNAME records is getting more attention, and it is likely that browsers will introduce the necessary APIs so that they can block or restrict this type of data access as well.